struct WorkData
{
int value;
int step_value;
int proc_times;
};
static
int ThrdFunc(struct WorkData *data)
{
int n = data->proc_times;
int x = data->step_value;
for(int i = 0; i < n; ++i)
data->value += x;
return 0;
}執行緒同步 4:為什麼出錯?
經過前面幾篇, 想必讀者已經對執行緒與其運作原理有了一定的認識,也能夠自己動手開始製做多執行緒的程式了。 但是當真正開始嘗試以後,應該很快就能發現一些奇怪的現象。 比如有些執行緒共同存取的變數好像偶爾會冒出怪怪的結果, 而如果共同存取的是一些比較複雜的物件如標準函式庫的容器等等的話, 可能還會冒出各種奇奇怪怪的異常或甚至導致程式當掉等等問題。 那麼這是怎麼回事呢?為什麼會出問題呢?
Race Condition
這種在多緒程式所容易產生的資料存取問題被稱為資料競爭(Race Condition)。 接下來讓我們使用一個範例來呈現這種問題。
下面是我們的執行緒函式,它的行為就是使用迴圈不斷將一個變數的值進行累加:
然後在主函式內建立 4 條同樣執行上面那個函式的執行緒, 並且傳遞給它們同一個資料結構,這樣它們就會一起對那同一個變數進行不斷累加的行為:
struct WorkData data =
{
.value = 0,
.step_value = 2,
.proc_times = 100000000,
};
static const int thrd_num = 4;
thrd_t thrd_list[thrd_num];
for(int i = 0; i < thrd_num; ++i)
{
int err = thrd_create(&thrd_list[i], (int(*)(void*)) ThrdFunc, &data);
assert( err == thrd_success );
}以上只顯示了關鍵重要的程式碼片段, 而完整的範例可以從這裡下載, 而在我的電腦上實際執行過之後的結果如下:
Finished, value=344688372/800000000, spend=1176從上面的程式碼中可以看到,指定給迴圈的循環次數是 100000000, 也就是每個執行緒都會跑過 1 億次累加計算。 那麼那個共同累加的變數初值為 0, 每個執行緒累加 1 億次,每次累加值為 2,又總共有 4 條執行緒一起工作, 因此最終計算完成的結果應該是 8 億; 然而實際執行結果卻只有 3 億多,這是怎麼回事呢?!
為什麼出錯?
當不同的執行緒共同讀寫同一個變數,或者說共同修改同一段記憶體的資料時, 就會發生資料競爭的情況,從而有機率導致發生不可預期的資料異常情況。 導致這種結果發生的原因主要有三:多指令工作、核心快取、以及執行順序所導致。
多指令工作
除非是系統性修習過資工專業,或是從電子電機相關領域念上來的人,
否則對於一般直接從高階程式語言入門學習的人來說,
應該一般不容易很快的理解到即便是一個看似簡單又單純的程式敘述,
其背後往往需要動用好多條 CPU 指令來完成。
例如上面的範例程式碼,
在執行緒函式中對那個 value 變數所進行的 data->value += x 這一條看似簡單無比的敘述,
背後真正完成這項操作的其實是以下數個指令的結果:
movq -24(%rbp), %rax ; 將 data 資料結構的地址讀入 RAX 暫存器
movl (%rax), %edx ; 將 data->value 的值讀入 EDX 暫存器
movl -4(%rbp), %eax ; 將 data->step_value 的值讀入 EAX 暫存器
addl %eax, %edx ; 將 EAX 與 EDX 的值相加,並將結果存回 EDX 暫存器
movl %edx, (%rax) ; 將 EDX 的值存入 data->value 變數內上面的指令呈現只是作者在我的電腦上編譯出來的的結果, 而讀者如果自己在家裡嘗試編譯範例程式碼的話,可能產生的結果會有些許不同。 這是因為不同的 CPU 所使用的指令集並不相同, 或者使用不同的編譯器與不同的編譯條件可能也會產生不同的指令的緣故, 然而具體細節雖然可能有些差異,但是指令結構基本大差不差,並不影響本篇敘事的邏輯和原理。
你看啊,這一個動作有這麼多的步驟要進行; 可如果命令進行到一半還沒全部做完的時候,執行緒就被排程器給切走了,那會發生什麼事?! 比如一個執行緒拿到那變數的值是 6,然後加 2 變成 8,再把 8 給存回變數。 但是在這個過程中可能執行緒自己曾經被切出去又切回來, 其它正在執行同樣事情的執行緒可能已經做過一次拿到 6 後加 2 再將 8 存回去的步驟, 但是這個執行緒並不知道這件事,於是就把它自以為已經累加過的,但實際上也同樣是 8 的數字給覆寫回去了。 導致雖然兩個執行緒都做過一次累加,但實際結果卻相當於只做過一次累加! 甚至於,執行緒切出去又切回來的時間內,搞不好其它執行緒已經執行過好幾回累加, 而那個數字可能實際已經變成 22 了; 然而當這個執行緒重新被切回來的時候,剛才發生過的這些事它當然都不知道, 於是又把它認為計算後的新值也就是 8 給覆寫回去了!
這就是為什麼執行緒共同存取覆寫資料的時候會導致競爭衝突的原因其一。 也許你會認為這問題是出在於執行緒切換的時間點不太好導致的, 如果讓排程器可以不在某些事情做到一半的時間點去切換, 而是能讓同一組相關的指令執行完再切換的話就能解決問題; 然而這個想法實際可行性並不高。 且先不論這會導致排程器的排程運算複雜到什麼程度,能不能夠被實現出來等問題, 即便排除萬難把能辦到這樣條件的排程器給造出來了,別忘了還有多核心、多 CPU 的情況, 它們可是真實的同時在平行運作的呢!甚至還可能每一條指令剛好都同時在進行的呢!
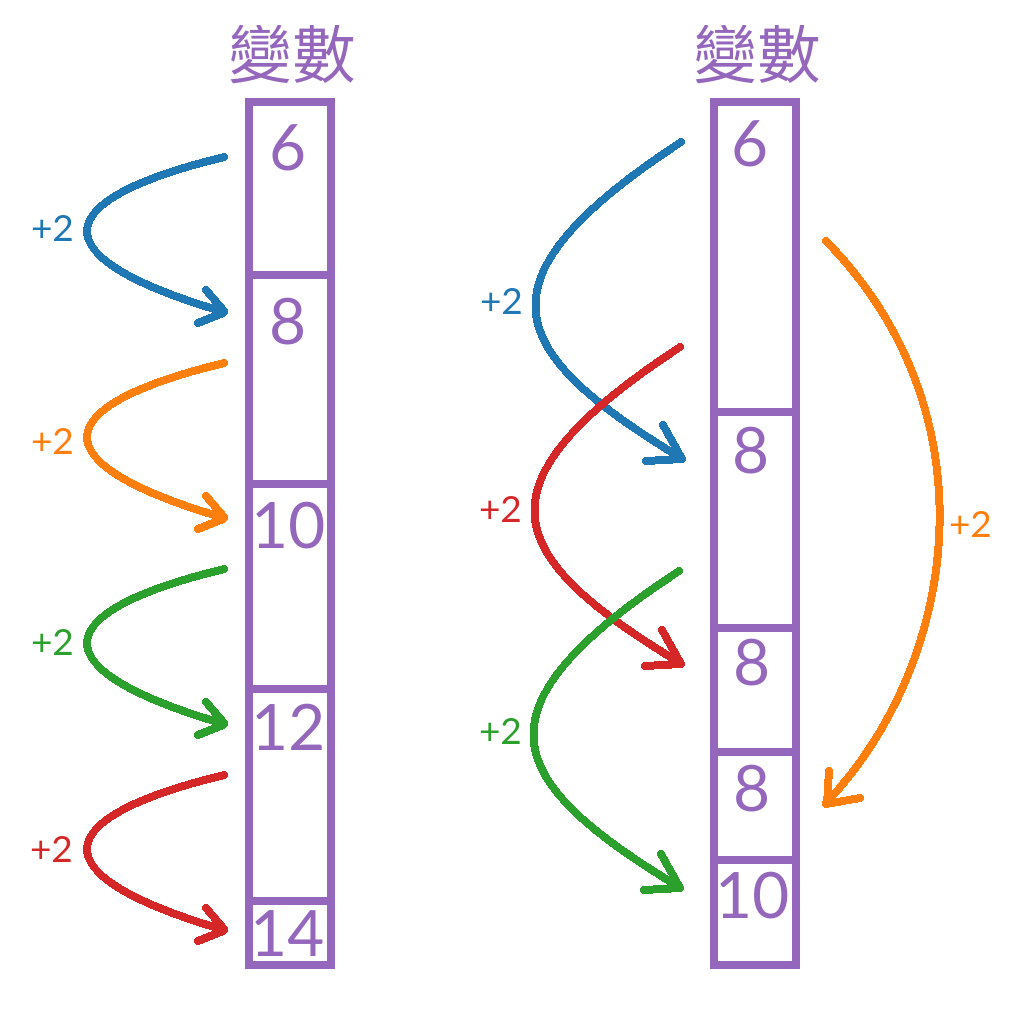
Figure 1. 左邊是單執行緒進行 4 次累加,解果正常且一如預期;右邊則是 4 條執行緒在可能任意的時間進行累加的結果,就發生了新舊狀態互相覆寫的情況!
核心快取
在前篇曾經解釋過, 我們人在工作的時候往往會先把一些會用到的資料從櫃子裡拿出來放到書桌上, 這樣即時要用的時候就可以直接轉頭到旁邊翻找參考,而不用一直來來回回去書櫃那裡, 而 CPU 其實也是一樣的! 電腦的主記憶體對 CPU 來說其實相當緩慢,因此 CPU 內部每個核心也有一份自己的小記憶體, 就像你桌面的空間不如書櫃那麼大,但是操作起來可快了, 這東西就被稱為「快取」(Cache)。 每當需要參用資料的時候,CPU 並不會每次都去主記憶體索取,而是如果快取有資料的話就會直接和快取要。 相對的,每次覆寫資料的時候也會先寫到快取內,後續等到合適的時間才會把快取更新的資料寫回主記憶體。
但是問題就來了,當系統存在多個 CPU 或多個核心的時候, 每個核心自己算自己的快取資料算的很開心,但是如果別的 CPU 核心其實也在自己的快取裡面修改這個 「理論上應該是同一個變數但實際上各核心自己有一份快取副本」的資料呢? 於是有一部份的資料衝突就有可能來源於這裡了! 然而這裡說的可能,那是因為源自於快取問題其實 CPU 本身的協作機制(通知快取失效) 就已經處理掉了大半,僅剩一部份還需要在後續的操作中加點料,而這一部份我放到下一篇再談。
執行順序
你知道嗎? 雖然我們一般認知程式都是一行一行的往下執行的,並且在學習的時候也是被這麼教導的, 然而實際上的程式並非如此! 比方以下面這一段程式碼為例:
e_b = e_i + e_u; // Line A
v_i = w * r * sin(e_i) / cos(e_u); // Line B
v_i_x = v_i * sin(e_b); // Line C
v_b = w * r * cos(e_i) / cos(e_u); // Line D
aoa = b - e_b; // Line E
cl = calc_cl(r, aoa); // Line F
cir = 0.5 * v_b * c * cl; // Line G
tlf = (2/PI) * acos(exp(( -k*( 1 - 2*r/dia ) )/( 2*sin(b_tip) ))); // Line H為了方便講解,上面這段程式碼的每一行註解都加上了 A~H 的標號。 就看上去的理解,這段程式碼的執行順序應該是 A → B → C → D → E → F → G → H, 然而實際上的執行順序卻可能是 D → F → B → A → G → E → C → H、 或者可能是 H → F → B → D → A → C → G → E,或者還有其它更多可能的排列組合。 那麼為什麼會有這種情況呢?答案是為了編譯最佳化(Compiler Optimisation)!
舉個例子,比如你媽要你去幫忙買個菜,回來的路上順便幫忙去繳個費, 回來之後順便洗兩杯米煮個飯,然後再出門幫媽媽把醬油還給對面的王阿姨。 這時我們就得到了一份指令清單,然而當落實到了實際的行動時, 我們卻很可能會調動這份清單的執行順序,而並不一定會嚴格的按照所交辦的順序。 為什麼呢?因為我們懶,想要省點事! 比方考量到買好了菜以後,回來的路上可能要背著一大堆東西去繳費好像不是很方便, 於是我們可能會選擇在去程空手的路上就先把費給繳了; 比方煮米這件事相當消耗時間,我們可能會選擇最先執行這件事, 這樣在等會出去的時間裡正好讓電鍋同步在煮米,而不是讓電鍋空等到我們回來之後才開始下鍋煮; 又比方說我們可能不想要出門兩趟,於是就選擇在煮好米之後出門先把醬油還給對面王阿姨, 然後去繳費,再買菜。
上面這個例子放到編譯器上面其實也是一樣的。 編譯器可能會有自己的想法,它可能會把你的程式敘述調換排列的順序,因為它認為這樣可以進行的更快速更順暢; 反正不論編譯器怎麼調換排序,只要最後執行出來的結果和嚴格按照順序執行出來的結果一樣就可以了! 於是回顧上面的範例片段,八行程式碼可以被編譯器隨意調動, 除了行 C 和行 E 不能被調到行 A 前面,因為那兩行的計算都需要依賴行 A 的結果; 同樣的,行 B 怎麼調都可以,就是不能調到行 C 前面,而行 G 必須在行 D 和行 F 的後面等; 甚至於計算最複雜的行 H 竟然不依賴前面任何一行的結果,於是可能反而第一個被送去執行等等。
程式指令這樣順序換來換去可能可以更高效的被執行,反正只要結果和沒換順序時一樣就可以; 然而當多緒同步運作的情況下,問題就可能產生了! 那些執行緒各自參照和共同參照的變數的存取覆寫順序可能有所不同,在單緒條件下反正最終的結果是一樣的, 然而在多緒平行互相參雜的時候,就可能因為執行緒之間原本就存在的互相截獲干涉等因素, 而導致對結果產生不可預期的結果偏差錯誤! 也許我們可以透過一些編譯器選項去禁止編譯器重排指令順序,然而這個問題依然可能會發生, 因為指令即便按照順序送給 CPU,CPU 卻也不一定會按照順序處理! 這就是 CPU 的「亂序執行」(Out-of-Order Execution)功能, 其同樣也是因為不同的指令可能需要消耗的資源與等待等不盡相同, 因而同樣 CPU 為了最佳化指令處理流程而自己做的優化。
這就是為什麼在多緒程式裡只要共同存取變數就可能會導致異常的三個原因。 在處理資料與數字計算等應用下,它可能會導致計算結果的偏差錯誤; 而如果共同存取的是一些比較複雜的並且涉及記憶體管理或系統資源管理的物件, 比如對標準 STL 容器的操作,則可能導致其內部狀態錯亂、違規存取,從而導致行程崩潰的結果! 對於這些問題當然存在許多解決方案,但是本篇只專注於解釋導致問題發生的原因, 因此那各種的執行緒同步技巧與方案等,就留待後續的篇章慢慢講解了。
為什麼多緒程式難?
不知道現在這個世代還有沒有人曾經被學長、前輩給恐嚇過類似像 「千萬不要嘗試多緒」、「多緒是非常難的東西」、「能單緒就只用單緒就好」、「沒事別搞死自己」 這樣的諄諄教誨耳提面命? 對於包括作者本人在內的,那些並未經受過紮實數位工程基礎訓練的半路出家程序員來說, 多緒程式確實存在許多令人摸不著頭腦的,讓人想不清原因的,又如午夜精靈那樣忽隱忽現的各種奇異又詭異的問題。 那麼為什麼多緒程式就這麼多問題,這麼容易讓人感受到挫折呢? 其實一言以蔽之就一句話:極強的隨機不確定性!
對於那些程式邏輯錯誤的查找工作(也就是程式「除錯」,或俗稱「抓蟲」), 其實通常來說害怕的並不是錯誤的嚴重性。 因為哪怕是天大的錯誤,只要它每次必然發生,或只要經過同樣的操作步驟之後必然觸發, 那就都不是什麼大事,錯誤被定位然後被解決都只是板上定釘的事情。 真正讓人感到頑固討厭、如貓捉老鼠那樣摧毀人心態的錯誤,是那種 忽明忽現、抓不到規律、摸不清底細, 你要抓它的時候守候整夜都不出現,你放棄的時候客戶又告訴你它出現了的錯誤; 而與執行緒有關的錯誤經常就是這一種型態!
經過本篇解釋到這裡,應以明白執行緒之間容易出的狀況主要在於執行流程的互相插斷、干涉。 然而這種影響卻是隨機的! 這次因為執行流程剛好斷在某個位置、或剛好在執行到某個位置的時候也恰好某另一條執行緒剛好執行了哪個動作, 於是導致現在出現的某個問題; 但是,同樣的問題卻很難重複顯現,因為我們基本無法控制不同流程之間的斷點情況。 也許下一次執行,剛好程式流錯開了,就沒發生任何問題; 或也許下一次執行遇到的是另一種執行情況的排列組合,顯現的是完全不一樣的另一個狀況; 甚至於,作業系統排程也在問題出現與否的行為中扮演關鍵性的角色, 畢竟所有的執行緒斷切回復全都是它在控制的! 意思就是說,甚至執行緒有關的問題出現或不出現、或者是呈現樣態的不同, 已經跳脫你的程式本身了,而是整個系統上所有正在運作的其它行程、以及作業系統本身的狀態通通都會影響進來, 可能每次執行出來的效果通通不一樣,每次出現異常的程式位置到處跳來跳去等; 或可能更加讓人惱怒的情況是重複執行一百遍通通剛好沒問題,然後在執行一萬遍之後才剛好抓到它那麼冒頭一次!
說了那麼多,那落實到實際的程式設計之中要怎麼樣去避免產生這些問題呢? 其實本來就應該要有的清晰的結構設計和模組責任劃分與內外區隔等設計原則, 其本就可以很大幅度的降低執行緒之間互相會產生交互作用的涵蓋範圍。 然後建立在前者之上,我認為最重要的一點原則就是 嚴格審視多緒交互影響範圍的邏輯程序,確保邏輯嚴謹;並且 絕不心存僥倖,只要一個有疑慮的情況有發生的可能性,哪怕你覺得只有怎樣低的發生機率,也必須要處理掉!
上面的第二點尤其更加重要,切勿存僥倖之心。 這怎麼說呢?如果你把範例程式碼的循環次數改成比如說 5 次或 10 次之類的就能感受到了, 可能絕大多數時候執行出來的結果都是一切正常! 說實在這些問題的發生是非常吃機率的,因此實際上很可能程式執行過有問題的程式碼非常多次卻都剛好沒有遇過問題; 然而機率低不表示絕對不會遇上,只要把程式放出去大量使用,那麼問題就總是會發生! 並且現實上真出問題的機率愈低的那種問題往往才是最討厭的問題! 所以有些時候特別在當我們寫程式寫累了的時候, 可能看到一段程式碼思索一下覺得或許哪個地方存在多緒交互運作之下邏輯不夠嚴謹的疑慮, 這時可能就容易懶下來,可能會產生「不會這麼巧吧?兩個操作也就一前一後的兩個連在一起的敘述, 得要多麼湊巧才會讓執行緒的切換正好斷在這?」這樣的取巧心理。 然而這就是危險的地方,因為如同前面說過的,機率即使再低,只要放出去大量執行就一定會遇上; 並且就是因為遇上這種問題的機率真的特別低, 於是它很可能就會成為往後不知何時何日將你絆在辦公桌前幾個星期找不著北的罪魁禍首!
關於範例程式
本篇所使用的那個累加數字的程式其實已經爛大街了,幾乎是所有論述到執行緒資料競爭話題時都會出現的程式碼。 我在寫作本篇的時候本來也想說是不是拿個更加實際一點的、更加有用點的程式來作範例, 然而找了一圈最後還是使用了這個最經典的累加程式。
主要的原因如同本篇後面所論述的內容,現實當中的執行緒衝突其實通常並不容易發生, 往往要累積執行次數與量之後才能靠著機率遇上一兩次。 然而作為一個示範則訴求卻剛好相反, 如果我說「你就拿去每天早上起來的時候都跑一遍,一個星期應該會遇到一回」, 或者說「每兩個小時就執行一遍,這樣一天應該有機會遇上一次」的話, 那麼這顯然不是一個好的示範程式, 而在這種情況下的一個所謂好的示範程式,就應該要能夠在每次執行的時候都能曝露問題。 這就是為什麼這個範例程式需要使用迴圈連著執行同樣的動作一億次的原因了。 而在我寫作本篇時自己的測試中,當迴圈次數少於一百次的時候,就已經幾乎不能夠顯現問題了!
而為什麼思來想去我最終還是沒有使用更加有趣的計算程序,最後還是回歸到累加計算呢? 因為作為示例程式其實還有一個也同樣重要的優求:要能夠明顯看出問題。 那麼要讓我們能夠明顯察覺異常,顯然就需要有一個很明顯正確的結果來作為對比, 而累加算法正好就是那種可以讓我們即便不執行程式都能知道它正確的結果應該要是什麼的算法!
最後還有一個相當重要的東西,如果讀者想要把範例程式拿到自己的電腦上編譯執行做測試的話,
麻煩一定要調整你自己編譯器的設定,然後將編譯最佳化給關掉!
編譯最佳化就如同本篇前面解釋過的執行順序最佳化的那部份一樣,
是編譯器可能覺得你寫的程式碼囉唆,於是它調整了你的程式碼,試圖取得更快的執行速度。
並且這種編譯最佳化行為並不僅止於如本篇所述的調整你的程式執行順序而已,
它可能還會濃縮、展開、刪除、變更、改寫你的程式碼,
反正目的就是盡可能找出某種方式給你的程式改頭換面,
雖然可能把內容改變了十萬八千里,但最後出來的結果和忠實呈現不動你程式碼的話出來的結果一樣,
並且還更加快速省事。
然而對於本篇範例程式碼來說這並不是好事,因為範例其實是一個實際應用中真實情況的簡化演示,
但是可能因為過於簡化了,導致編譯器覺得
「你寫這東西怎麼這麼蠢啊?改成這樣這樣,你看不是一下就出來了嗎!」
最後反而重現不出我們原來所預期的效果。
比如我在做測試的時候就曾嘗試把最佳化開到最大,結果程式休一下零秒就跑完了!(原來需要一秒多!)
一看編出來的結果,原來是編譯器覺得我用迴圈一次一次累加一億次太蠢太費事,
於是它直接改成了 data->value += 2 * 100000000;
雖然就結果來說它做的相當好,但反而在本篇的訴求上就完全不是想要的效果!
因此如果你想要自己編譯執行本篇範例,請記得關閉你的編譯器的最佳化編譯功能; 如果你使用的是 GCC 的話,那麼可以加入編譯選項 “-O0” 來關閉最佳化。 此外,如果你想要觀看編譯器編譯後真正送去執行的東西的話, 可以設定將編譯器編譯出組合語言這個步驟就停止並輸出。 組合語言雖然還不是機器碼,但與機器碼之間基本絕大部份都是 1:1 直接對應的, 因此對於分析理解的用途來說已經相當於直接閱讀機器碼了! 然而可能並不是每個編譯器都支援把程式碼編譯成組合語言並輸出的功能, 但如果你使用的是 GCC 的話,那麼加入 “-S” 編譯選項就可以做到這件事, 並且本篇所使用的組合語言分析也都是這麼得來的! 另外,不同 CPU 的指令集可能並不相同, 因此如果你不是在 x86 電腦上去編譯組合語言的話,可能會看到與本篇示例差異巨大的結果, 但這都是正常的現象。
下一篇:「執行緒同步 5:原子變數」